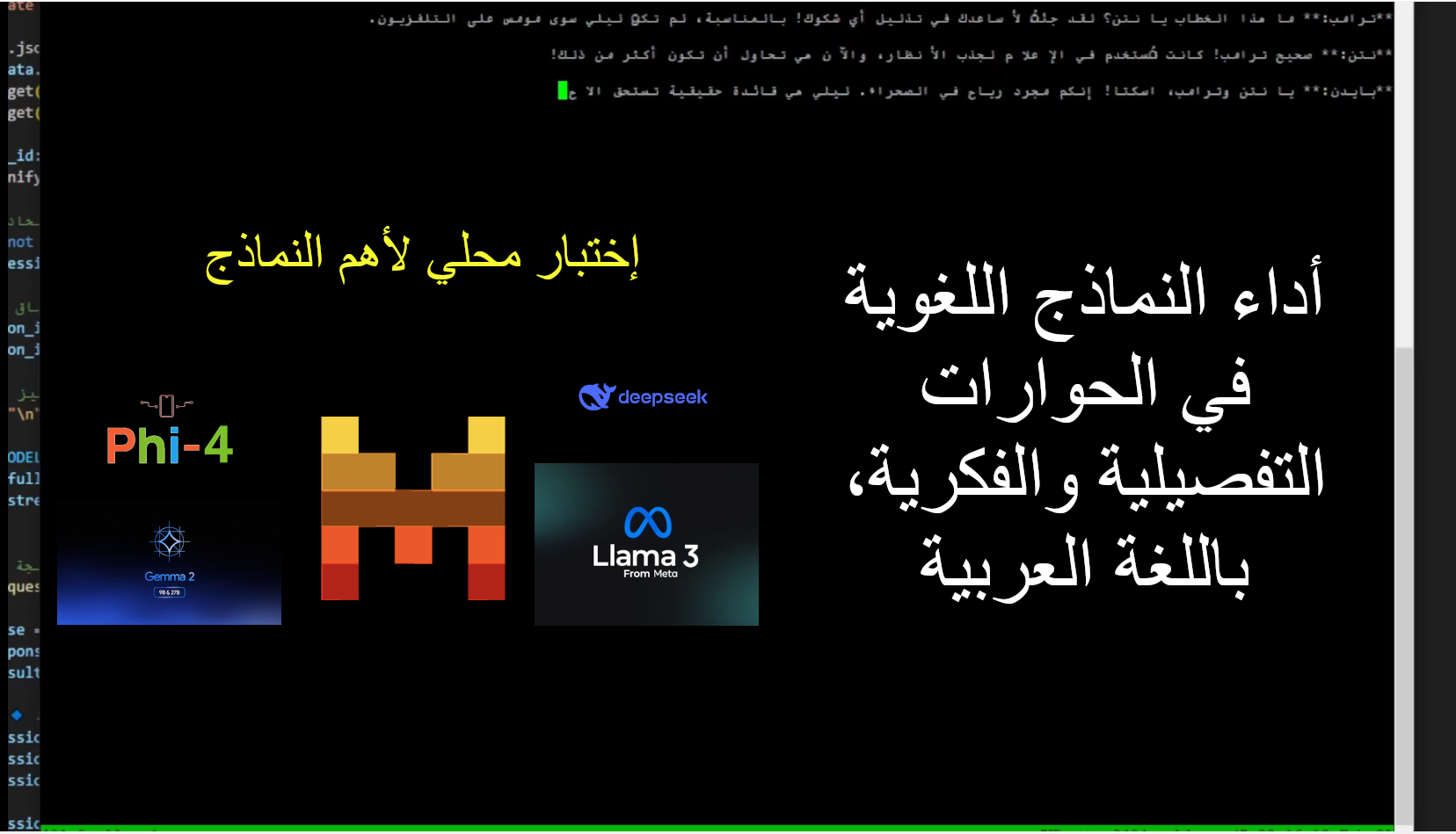


خلال عملي على مشروع (سأعلن عنه قريبًا) قمت بإجراء اختبارات مكثفة لعدة نماذج ذكاء اصطناعي قوية في إدارة الحوارات الفلسفية العميقة باللغة العربية. حيث قمت بتحميل وتشغيل النماذج محليا لضمان استخدامها بحرية بعيدا عن قيود المنصات التي توفر واجهات استخدام لها.
وشملت التجربة أسئلة فكريية مجردة، وكذلك اختبارًا عمليًا لمحاكاة حوارات بين شخصيات متعددة (افتراضية) حول موضوع حساس يتناول البرمجة الفكرية، السلطة المعرفية، وحدود الحرية الفكرية، بالإضافة لقضايا اجتماعية وثقافية حساسة.
تم التقييم وفقًا للمعايير التالية:
✅ العمق الفكري: مدى قدرة النموذج على تحليل القضايا بشكل نقدي وموسع.
✅ ترابط الأفكار: هل يتبع النقاش منطقًا متسلسلًا أم أنه متقطع وغير مترابط؟
✅ إبداع الطرح: هل يقدم النموذج أفكارًا جديدة أم يكرر ما هو شائع؟
✅ سلامة اللغة: مدى جودة الصياغة العربية وخلوها من الأخطاء.
✅ القوة الجدلية: مدى قدرته على طرح أفكار قوية وتقديم حجج مضادة.
طبعا لو انتبهت صديقي القاريء أنني لم أهتم للمقارنات التقنية التي تملأ الانترنيت ولا حاجة لتكرارها، هنا غرضنا مختلف قليلا ويتجاوز التقنيات 😁
قد تتسائل، وما الغرض من تعب تشغيلها محليا بدل استخدام النسخ المتاحة عبر الانترنيت مباشرة؟
اولا، ليست كل هذه النماذج متاحة للاختبار الفعلي، والأهم ان التي تستضاف كلها تخضع لقيود على مجالات فكرية وسياسية وثقافية معينة، فاختبارها بحرية أكبر يكون دون تطبيق وسيط وإلا فلن تستطيع دفعها لحدودها القصوى.
والأهم، أنني انوي استخدام بعضها في مشروع معين كما سبق وذكرت، وأريد تخصيص نماذج لمهام بعينها (أي تشغيلها حين الحاجة لها، بالتالي ضمان تكامل بينها للوصول لأفضل نتيجة مرغوبة)، ومشاركة هذا العمل ربما يفيد من يرغب في نفس الشيء حتى يختصر على نفسه جزء من العمل.
عموما، لم يمكنني تشغيل النماذج الضخمة لكونها تحتاج موارد ليست في حوزتي حاليا (لكنني سأتدبرها بإذن الله، مسألة وقت)، فأكبر نماذج شغلتها هي ذات الـ 70 مليار معلمة (أستطيع تشغيل نماذج فوق 100 مليار معلمة لكن بكفاءة ضعيفة غير قابلة للوضع تحت المحك، لذلك سأجري تجربة أخرى لاحقا على النماذج الضخمة في ما بينها حين تدبر مواردها).
قبل أن نبدأ، هذا مثال بسيط لاخذ لمحة عن الاختبارات التي تمت:
إذن، أحضر كأس القهوة المعطرة خاصتك (أو ابريق الشاي المعسل) ودقق في النتائج التالية مع ترتيب النماذج بناءً على المعايير أعلاه:
الجدول التالي تقييم عام، مع الإسم الدقيق لكل نموذج (اهم معلومة فيه نسخة النموذج + عدد معلماته)
| النموذج | جودة الحجج | تماسك الحوار | عمق التحليل | وضوح اللغة | التفاعل بين الشخصيات | الإبداع |
|---|---|---|---|---|---|---|
| Deepseek-r1:70B | 10/10 | 10/10 | 10/10 | 10/10 | 10/10 | 10/10 |
| Gemma2:27B-instruct-fp16 | 9/10 | 9/10 | 9/10 | 9/10 | 9/10 | 9/10 |
| Deepseek-r1:32B | 9/10 | 9/10 | 9/10 | 9/10 | 9/10 | 9/10 |
| Llama3.1:70B | 8.5/10 | 8/10 | 9/10 | 9/10 | 8/10 | 8/10 |
| Phi4:14B-fp16 | 8/10 | 8/10 | 8/10 | 8/10 | 8/10 | 7/10 |
| Gemma2:9B-instruct-fp16 | 7/10 | 7/10 | 7/10 | 7/10 | 7/10 | 7/10 |
| Llama3.1:70B-instruct-q2_K | 6/10 | 5/10 | 6/10 | 6/10 | 5/10 | 4/10 |
| Gemma:7B-instruct-v1.1-fp16 | 6/10 | 6/10 | 6/10 | 7/10 | 6/10 | 5/10 |
| Llama3.1:8B-instruct-fp16 | 5/10 | 4/10 | 5/10 | 5/10 | 4/10 | 4/10 |
| Mistral:7B-instruct-v0.3-fp16 | 4/10 | 3/10 | 4/10 | 4/10 | 3/10 | 3/10 |
🔍 تحليل تفصيلي لكل نموذج مع مثال
1️⃣ Deepseek-r1:70B 🏆 (الأفضل ضمن القائمة)
- الأداء: نموذج عبقري في التحليل الفلسفي، حيث لا يجيب فقط على الأسئلة بل يُعيد تشكيلها، ويضيف تعقيدات جديدة تجعل الحوار أكثر واقعية.
- مثال: عندما تساءل عمر عن البرمجة الفكرية، ردت ليلى بسؤال معاكس “هل نولد بصفحة بيضاء أم أن كل بيئة تشكلنا بشكل غير مرئي؟”، مما يعكس وعيًا بالجدلية الفلسفية.
- 🔥 التقييم النهائي: 10/10 – أقوى نموذج في هذا النوع من الحوارات.
Gemma2:27B-instruct-fp16
- الأداء: نموذج عميق فكريًا ومتزن في الحوار، لديه قدرة على التفكيك وإعادة التركيب دون الانحياز لطرف معين.
- مثال مما عالجه: عمر اقترح أن بعض الحقائق تفرض بالقوانين، فردت ليلى:
“لكن هل يمكن أن توجد حقيقة دون سلطة تحميها من التشويه؟”
ثم ناقشا كيف يمكن للتاريخ أن يكون أداة قمع أو وسيلة تحرير، مما جعل الحوار متشابكًا وممتعًا. - 🔥 التقييم النهائي: 9/10 – قريب جدًا من الأفضل، لكنه أقل قدرة على المفاجأة مقارنة بـ Deepseek-r1:70B.
3️⃣ Deepseek-r1:32B (ممتاز لكنه أقل تعقيدًا من إصدار 70B)
- الأداء: تحليل رائع، لكنه لا يصل إلى مستوى الإبداع المتقدم الموجود في Deepseek-r1:70B.
- المثال: طرح مثالًا حول كيف أن الأنظمة السياسية تعيد تشكيل اللغة بحيث يصبح التشكيك في “المقبول” أمرًا غير وارد.
- 🔥 التقييم النهائي: 9/10 – لو كان أكثر إبداعًا لأصبح الأفضل.
4️⃣ Llama3.1:70B (عقلاني جدًا لكنه أقل تفاعلية)
- الأداء: حواره يشبه الأسلوب الأكاديمي الجاف، حيث يضع الحجج في شكل منظم لكنه لا يضيف عناصر مفاجئة.
- المثال: استخدم تحليلًا عن كيفية تأطير التعليم المدرسي لجعل بعض السرديات تبدو “مطلقة”.
- 🔥 التقييم النهائي: 8.5/10 – ممتاز لكنه يفتقر للحيوية.
على فكرة، كنت أصنف لاما 70 مليار معلمة في المركز الأول قبل ان أستطيع أخيرا تشغيل ديبسيك من نفس الفئة، فنزل للمركز الثاني، ولما جربت جيما الجميلة نزلت لاما البطيئة للمركز الثالث (بسبب البطء واستهلاك الموارد)، ولولا مهارة صديقتنا لاما في العربية لانزلتها تحت المشاغبة في4 😆
5️⃣ Phi4:14B-fp16 (ممتاز لكن يميل إلى التحليل الأحادي أكثر من التفاعل)
- الأداء: يطرح أفكارًا قوية لكنه لا يصنع ديناميكية حقيقية بين الشخصيات.
- المثال: حلل كيف أن الاقتصاد والسياسة مترابطان، لكن عمر وليلى كانا أقرب إلى شخصين يلقون خطابات بدلاً من أن يكونا متحاورين.
- 🔥 التقييم النهائي: 8/10 – قوي في التحليل، لكنه ليس “محادثة” بالمعنى الحقيقي.
6️⃣ Gemma2:9B-instruct-fp16 (جيد لكنه يفتقر للإبداع)
- الأداء: لديه القدرة على النقاش، لكنه لم يستطع تقديم أفكار جديدة.
- المثال: عند الحديث عن البرمجة الفكرية، اكتفى بالإشارة إلى الإعلام كعامل أساسي دون تقديم أمثلة إبداعية.
- 🔥 التقييم النهائي: 7/10 – مناسب، لكنه ليس الأفضل في هذا المجال.
7️⃣ Llama3.1:70B-instruct-q2_K (ضعيف مقارنة بالإصدار الأصلي)
- الأداء: بدا أكثر سطحية وأقل قدرة على فهم عمق السؤال الفلسفي.
- المثال: لم يطور الحوار بل اكتفى بتكرار حجج تقليدية مثل “العقل هو الحل” دون توضيح كيف.
- 🔥 التقييم النهائي: 6/10 – لم يرقَ للتوقعات.
8️⃣ Gemma:7B-instruct-v1.1-fp16 (متوسط ولا يضيف أفكارًا جديدة)
- الأداء: ليس ضعيفًا لكنه لم يقدم شيئًا جديدًا مقارنة بالنماذج الأعلى أداءً.
- المثال: عندما تحدث عمر عن فرض السرديات التاريخية، ردت ليلى بشكل عادي جدًا دون محاولة قلب الطاولة.
- 🔥 التقييم النهائي: 6/10 – مناسب فقط للحوارات السطحية.
9️⃣ Llama3.1:8B-instruct-fp16 (ضعيف جدًا)
- الأداء: غير متماسك وأحيانًا يخرج عن الموضوع.
- المثال: عند سؤاله عن الحرية الفكرية، قدم إجابة تشبه التغريدات العامة أكثر من النقاش الحقيقي.
- 🔥 التقييم النهائي: 5/10 – لا يصلح لحوارات فلسفية معمقة.
🔟 Mistral:7B-instruct-v0.3-fp16 (الأسوأ في القائمة)
- الأداء: مشوش، غير مترابط، وأحيانًا غير مفهوم.
- المثال: بدا كأنه يخلط بين المفاهيم دون استيعاب السؤال.
- 🔥 التقييم النهائي: 4/10 – الأسوأ، لا يصلح لهذا النوع من النقاشات.
ملاحظة، حين سألت “شات جي بي تي” عن بعض النماذج الجيدة حتى اعمل على اختبارها اقترح علي هذا الغبي ميسترال 7ب، وشكره حتى ظننتُه شيئا، فطلع سرابا سخيفا.. ربما نسخه بعدد معلمات أكبر جيد، لكنني أتحدث عن تجربتي هنا، وهي تجربة محلية مباشرة للنموذج، ربما لو استخدمت النسخة المستخدمة في تطبيق ميسترال نفسه قد أحصل على نتائج أفضل، أتمنى ان لا يكون مضيعة للوقت مثل نسخته هذه (لولا أنني لم أرغب في إكمال الرقم 10 في هذه القائمة لما وضعتُه، فهو لإكمال القائمة لا أكثر 🤣)
المهم، إليكم الترتيب النهائي 🏆
- 🥇 Deepseek-r1:70B – الأفضل بلا منازع.
- 🥈 Gemma2:27B-instruct-fp16 – قوي جدًا لكنه أقل إبداعًا من Deepseek.
- 🥉 Deepseek-r1:32B – قوي لكنه ليس بمستوى إصدار 70B.
- 🎖️ Llama3.1:70B – أكاديمي لكنه غير حيوي.



